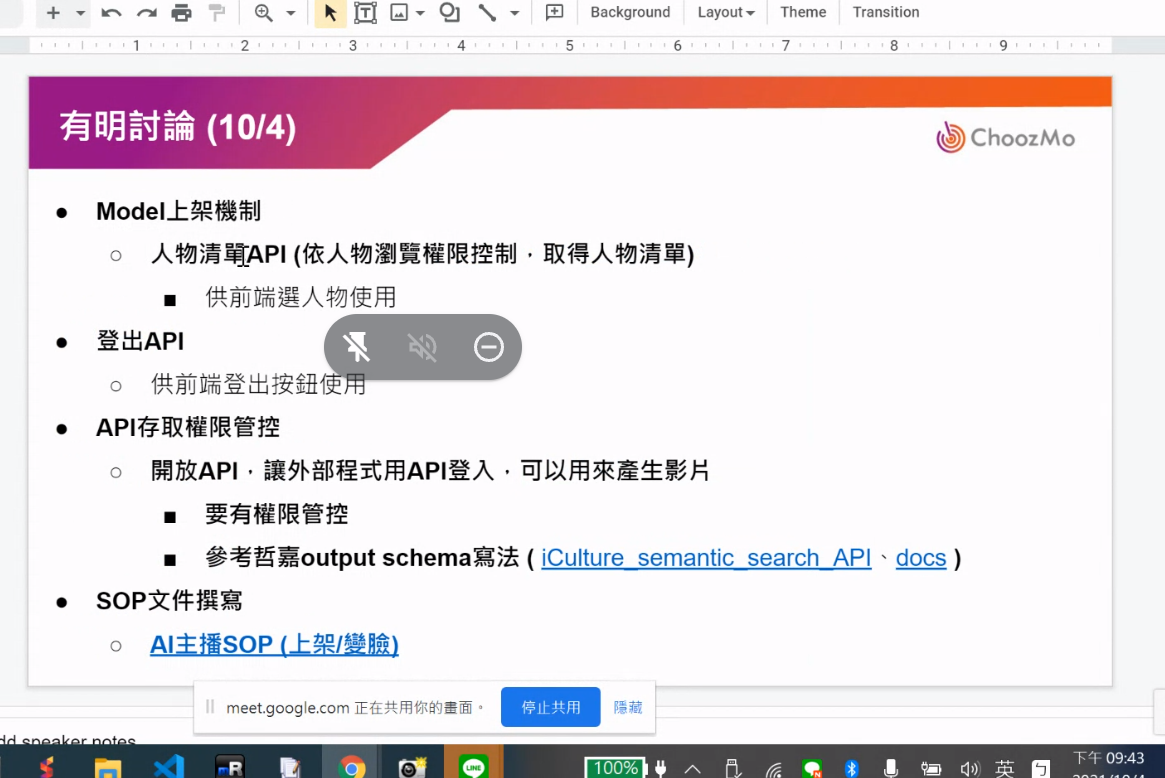
|
|
@@ -415,10 +415,10 @@ async def create_upload_file(file: UploadFile = File(...)):
|
|
|
@app.post("/upload_pttx/")
|
|
|
async def upload_pttx(file: UploadFile = File(...)):
|
|
|
try:
|
|
|
- if "_" in file.filename:
|
|
|
- return {'msg':{'eng':'symbol"_" is not allowed in file name','zh':'檔案無法使用檔名不能含有"_"符號'}}
|
|
|
+ if "#" in file.filename:
|
|
|
+ return {'msg':{'eng':'symbol"#" is not allowed in file name','zh':'檔案無法使用檔名不能含有"#"符號'}}
|
|
|
else:
|
|
|
- pttx_name = file.filename+'_'+str(time.time()).replace('.','')
|
|
|
+ pttx_name = file.filename.replace('.pptx','#')+str(time.time()).replace('.','')+'.pptx'
|
|
|
with open(pttx_dest+pttx_name, "wb+") as file_object:
|
|
|
file_object.write(file.file.read())
|
|
|
return {"msg": resource_server+pttx_sub_folder+pttx_name}
|
|
|
@@ -426,7 +426,6 @@ async def upload_pttx(file: UploadFile = File(...)):
|
|
|
logging.error(traceback.format_exc())
|
|
|
return {'msg':{'eng':'file cant be prossessed','zh':'檔案無法使用'}}
|
|
|
|
|
|
-
|
|
|
@app.post("/make_anchor_video_gSlide")
|
|
|
async def make_anchor_video_gSlide(req:util.models.gSlide_req,token: str = Depends(oauth2_scheme)):
|
|
|
if req.url_type == 0:
|
|
|
@@ -434,29 +433,23 @@ async def make_anchor_video_gSlide(req:util.models.gSlide_req,token: str = Depen
|
|
|
else :
|
|
|
filename = req.slide_url.replace(resource_server+pttx_sub_folder,resource_folder+pttx_sub_folder)
|
|
|
name, text_content, image_urls = gSlide.parse_pttx_url(filename,img_upload_folder,resource_server+tmp_img_sub_folder,eng=False)
|
|
|
+
|
|
|
if len(image_urls) != len(text_content):
|
|
|
return {'msg':{'eng':'number of subtitles and images(videos) should be the same','zh':'副標題數量、圖片(影片)數量以及台詞數量必須一致'}}
|
|
|
+
|
|
|
for idx in range(len(image_urls)):
|
|
|
if 'http' not in image_urls[idx]:
|
|
|
image_urls[idx] = 'http://'+image_urls[idx]
|
|
|
- if req.multiLang==0:
|
|
|
- for txt in text_content:
|
|
|
- if re.search('[a-zA-Z]', txt) !=None:
|
|
|
- print('語言錯誤')
|
|
|
- return {'msg':{'eng':'English is not allowed in subtitles','zh':'輸入字串不能包含英文字!'}}
|
|
|
- if re.search(',', txt) !=None:
|
|
|
- print('包含非法符號')
|
|
|
- return {'msg':{'eng':'symbol "," is not allowede','zh':'輸入不能含有","符號'}}
|
|
|
+
|
|
|
+ mulitLang, hasError = Check_text_content(text_content)
|
|
|
+ if hasError is not False :
|
|
|
+ return hasError
|
|
|
+
|
|
|
+ imgError = Check_image_url(image_urls)
|
|
|
+ if imgError is not False :
|
|
|
+ return imgError
|
|
|
+
|
|
|
name_hash = str(time.time()).replace('.','')
|
|
|
- for imgu in image_urls:
|
|
|
- try:
|
|
|
- if get_url_type(imgu) =='video/mp4':
|
|
|
- r=requests.get(imgu)
|
|
|
- else:
|
|
|
- im = Image.open(requests.get(imgu, stream=True).raw)
|
|
|
- im= im.convert("RGB")
|
|
|
- except:
|
|
|
- return {'msg':{'eng':req.imgurl+'cant be proccessed','zh':"無法辨別圖片網址"+req.imgurl}}
|
|
|
user_id = get_user_id(token)
|
|
|
proto_req = util.models.request_normal()
|
|
|
proto_req.text_content = text_content
|
|
|
@@ -508,7 +501,6 @@ async def make_anchor_video_long(req:util.models.request,token: str = Depends(oa
|
|
|
returnMsg = {'msg':{'eng':'Processing video requires a few minutes, please wait for notification','zh':'影片處理需要數分鐘,請等待通知'}}
|
|
|
return returnMsg
|
|
|
|
|
|
-
|
|
|
@app.post("/make_anchor_video")
|
|
|
async def make_anchor_video(req:util.models.request,token: str = Depends(oauth2_scheme)):
|
|
|
db_check()
|
|
|
@@ -540,6 +532,43 @@ async def make_anchor_video(req:util.models.request,token: str = Depends(oauth2_
|
|
|
x = threading.Thread(target=gen_video_queue, args=(name_hash,req.name, req.text_content, req.image_urls,int(req.avatar),req.multiLang,video_id,user_id))
|
|
|
x.start()
|
|
|
|
|
|
+ if first(db.query('SELECT COUNT(1) FROM video_queue'))['COUNT(1)'] >= 3:
|
|
|
+ return {'msg':{'eng':'There are many videos have been processing, please wait.','zh':'目前有多部影片處理中,煩請耐心等候'}}
|
|
|
+ else:
|
|
|
+ return {'msg':{'eng':'Processing video requires a few minutes, please wait for notification','zh':'影片處理需要數分鐘,請等待通知'}}
|
|
|
+ return {'msg':'ok'}
|
|
|
+#not auth
|
|
|
+@app.post("/make_anchor_video_noAuth")
|
|
|
+async def make_anchor_video_noAuth(req:util.models.request):
|
|
|
+ db_check()
|
|
|
+ if len(req.image_urls) != len(req.text_content):
|
|
|
+ return {'msg':{'eng':'number of subtitles and images(videos) should be the same','zh':'副標題數量、圖片(影片)數量以及台詞數量必須一致'}}
|
|
|
+ for idx in range(len(req.image_urls)):
|
|
|
+ if 'http' not in req.image_urls[idx]:
|
|
|
+ req.image_urls[idx] = 'http://'+req.image_urls[idx]
|
|
|
+ if req.multiLang==0:
|
|
|
+ for txt in req.text_content:
|
|
|
+ if re.search('[a-zA-Z]', txt) !=None:
|
|
|
+ print('語言錯誤')
|
|
|
+ return {'msg':{'eng':'English is not allowed in subtitles','zh':'輸入字串不能包含英文字!'}}
|
|
|
+ if re.search(',', txt) !=None:
|
|
|
+ print('包含非法符號')
|
|
|
+ return {'msg':{'eng':'symbol "," is not allowede','zh':'輸入不能含有","符號'}}
|
|
|
+ name_hash = str(time.time()).replace('.','')
|
|
|
+ for imgu in req.image_urls:
|
|
|
+ try:
|
|
|
+ if get_url_type(imgu) =='video/mp4':
|
|
|
+ r=requests.get(imgu)
|
|
|
+ else:
|
|
|
+ im = Image.open(requests.get(imgu, stream=True).raw)
|
|
|
+ im= im.convert("RGB")
|
|
|
+ except:
|
|
|
+ return {'msg':{'eng':req.imgurl+'cant be proccessed','zh':"無法辨別圖片網址"+req.imgurl}}
|
|
|
+ user_id = get_user_id(token)
|
|
|
+ video_id = save_history(req,name_hash,user_id)
|
|
|
+ x = threading.Thread(target=gen_video_queue, args=(name_hash,req.name, req.text_content, req.image_urls,int(req.avatar),req.multiLang,video_id,user_id))
|
|
|
+ x.start()
|
|
|
+
|
|
|
if first(db.query('SELECT COUNT(1) FROM video_queue'))['COUNT(1)'] >= 3:
|
|
|
return {'msg':{'eng':'There are many videos have been processing, please wait.','zh':'目前有多部影片處理中,煩請耐心等候'}}
|
|
|
else:
|
|
|
@@ -654,6 +683,15 @@ async def history_input(token: str = Depends(oauth2_scheme)):
|
|
|
logs.append({'id':row['id'],'name':row['name'],'avatar':row['avatar'],'text_content':row['text_content'].split(','),'link':row['link'],'image_urls':row['image_urls'].split(',')})
|
|
|
return logs
|
|
|
|
|
|
+@app.post("/history_input_noAuth")
|
|
|
+async def history_input_noAuth():
|
|
|
+ db_check()
|
|
|
+ statement = 'SELECT * FROM history_input ORDER BY timestamp DESC LIMIT 50'
|
|
|
+
|
|
|
+ logs = []
|
|
|
+ for row in db.query(statement):
|
|
|
+ logs.append({'id':row['id'],'name':row['name'],'avatar':row['avatar'],'text_content':row['text_content'].split(','),'link':row['link'],'image_urls':row['image_urls'].split(',')})
|
|
|
+ return logs
|
|
|
|
|
|
|
|
|
@AuthJWT.load_config
|
|
|
@@ -763,9 +801,40 @@ def notify_group(msg):
|
|
|
headers = {"Authorization": "Bearer " + gid,"Content-Type": "application/x-www-form-urlencoded"}
|
|
|
r = requests.post("https://notify-api.line.me/api/notify",headers=headers, params={"message": msg})
|
|
|
|
|
|
+def notify_choozmo(msg):
|
|
|
+ #'WekCRfnAirSiSxALiD6gcm0B56EejsoK89zFbIaiZQD' is ChoozmoTeam
|
|
|
+ glist = ['WekCRfnAirSiSxALiD6gcm0B56EejsoK89zFbIaiZQD']
|
|
|
+ for gid in glist:
|
|
|
+ headers = {"Authorization": "Bearer " + gid,"Content-Type": "application/x-www-form-urlencoded"}
|
|
|
+ r = requests.post("https://notify-api.line.me/api/notify",headers=headers, params={"message": msg})
|
|
|
+
|
|
|
+def Check_text_content(text_content):
|
|
|
+ mulitLang = 0
|
|
|
+ status = False
|
|
|
+ for txt in text_content:
|
|
|
+ if re.search('[a-zA-Z]', txt) !=None:
|
|
|
+ mulitLang = 1
|
|
|
+ if re.search(',', txt) !=None:
|
|
|
+ print('包含非法符號')
|
|
|
+ status = {'msg':{'eng':'symbol "," is not allowede','zh':'輸入不能含有","符號'}}
|
|
|
+ return mulitLang, status
|
|
|
+
|
|
|
+def Check_image_url(image_urls):
|
|
|
+ status =False
|
|
|
+ for imgu in image_urls:
|
|
|
+ try:
|
|
|
+ if get_url_type(imgu) =='video/mp4':
|
|
|
+ r=requests.get(imgu)
|
|
|
+ else:
|
|
|
+ im = Image.open(requests.get(imgu, stream=True).raw)
|
|
|
+ im= im.convert("RGB")
|
|
|
+ except:
|
|
|
+ status = {'msg':{'eng':req.imgurl+'cant be proccessed','zh':"無法辨別圖片網址"+req.imgurl}}
|
|
|
+ return status
|
|
|
+
|
|
|
|
|
|
def gen_video_long_queue(name_hash,name,text_content, image_urls,avatar,multiLang,video_id,user_id):
|
|
|
- db_check()
|
|
|
+ db = dataset.connect('mysql://choozmo:pAssw0rd@db.ptt.cx:3306/AI_anchor?charset=utf8mb4')
|
|
|
if name_hash == 'keepRunning':
|
|
|
if first(db.query('SELECT COUNT(1) FROM video_queue where video_type="longvideo"'))['COUNT(1)'] == 0:
|
|
|
return
|
|
|
@@ -829,9 +898,10 @@ def gen_video_long_queue(name_hash,name,text_content, image_urls,avatar,multiLan
|
|
|
notify_group('長影片錯誤-測試')
|
|
|
db['video_queue'].delete(id=top1['id'])
|
|
|
db.query('UPDATE video_queue_status SET status = 0')
|
|
|
+ db.close()
|
|
|
|
|
|
def gen_video_queue(name_hash,name,text_content, image_urls,avatar,multiLang,video_id,user_id):
|
|
|
- db_check()
|
|
|
+ db = dataset.connect('mysql://choozmo:pAssw0rd@db.ptt.cx:3306/AI_anchor?charset=utf8mb4')
|
|
|
if name_hash == 'keepRunning':
|
|
|
if first(db.query('SELECT COUNT(1) FROM video_queue where video_type="short"'))['COUNT(1)'] == 0:
|
|
|
return
|
|
|
@@ -895,9 +965,10 @@ def gen_video_queue(name_hash,name,text_content, image_urls,avatar,multiLang,vid
|
|
|
notify_group('影片錯誤')
|
|
|
db['video_queue'].delete(id=top1['id'])
|
|
|
db.query('UPDATE video_queue_status SET status = 0')
|
|
|
+ db.close()
|
|
|
|
|
|
def gen_video_queue_eng(name_hash,name,text_content, image_urls,sub_titles,avatar,video_id):
|
|
|
- db_check()
|
|
|
+ db = dataset.connect('mysql://choozmo:pAssw0rd@db.ptt.cx:3306/AI_anchor?charset=utf8mb4')
|
|
|
if name_hash == 'keepRunning':
|
|
|
if first(db.query('SELECT COUNT(1) FROM video_queue where video_type="eng"'))['COUNT(1)'] == 0:
|
|
|
return
|
|
|
@@ -941,6 +1012,7 @@ def gen_video_queue_eng(name_hash,name,text_content, image_urls,sub_titles,avata
|
|
|
notify_group('影片錯誤')
|
|
|
db['video_queue'].delete(id=top1['id'])
|
|
|
db.query('UPDATE video_queue_status SET status = 0')
|
|
|
+ db.close()
|
|
|
|
|
|
def gen_avatar(name_hash, imgurl):
|
|
|
db_check()
|
|
|
@@ -1029,7 +1101,7 @@ def call_speech(text,speaker):
|
|
|
fw.close()
|
|
|
shutil.copy(text+'.wav',speech_dest+text+'.wav')
|
|
|
os.remove(text+'.wav')
|
|
|
- notify_group("speech at www.choozmo.com:8168/speech/"+text+".wav")
|
|
|
+ notify_choozmo("speech at www.choozmo.com:8168/speech/"+text+".wav")
|
|
|
|
|
|
|
|
|
def verify_jwt_token(token):
|
|
|
@@ -1042,7 +1114,8 @@ def verify_jwt_token(token):
|
|
|
return 'please login again'
|
|
|
def db_check():
|
|
|
global db
|
|
|
- db.close()
|
|
|
+ if db!=None:
|
|
|
+ db.close()
|
|
|
db = dataset.connect('mysql://choozmo:pAssw0rd@db.ptt.cx:3306/AI_anchor?charset=utf8mb4')
|
|
|
|
|
|
|

 huai-sian
huai-sian
{kind=link}