|
|
@@ -34,6 +34,7 @@ retriever = create_faiss_retriever()
|
|
|
|
|
|
# text-to-sql usage
|
|
|
from text_to_sql2 import run, get_query, query_to_nl, table_description
|
|
|
+from post_processing_sqlparse import get_query_columns, parse_sql_for_stock_info, get_table_name
|
|
|
|
|
|
|
|
|
def faiss_query(question: str, docs, llm, multi_query: bool = False) -> str:
|
|
|
@@ -58,7 +59,7 @@ def faiss_query(question: str, docs, llm, multi_query: bool = False) -> str:
|
|
|
{context}
|
|
|
|
|
|
Question: {question}
|
|
|
- 用繁體中文
|
|
|
+ 用繁體中文回答問題
|
|
|
<|eot_id|>
|
|
|
|
|
|
<|start_header_id|>assistant<|end_header_id|>
|
|
|
@@ -135,7 +136,21 @@ def _query_to_nl(question: str, query: str):
|
|
|
answer = query_to_nl(db, question, query, llm)
|
|
|
return answer
|
|
|
|
|
|
-
|
|
|
+def generate_additional_detail(sql_query):
|
|
|
+ terms = parse_sql_for_stock_info(sql_query)
|
|
|
+ answer = ""
|
|
|
+ for term in terms:
|
|
|
+ if term is None: continue
|
|
|
+ question_format = [f"什麼是{term}?", f"{term}的用途是什麼", f"如何計算{term}?"]
|
|
|
+ for question in question_format:
|
|
|
+ # question = f"什麼是{term}?"
|
|
|
+ documents = retriever.get_relevant_documents(question, k=30)
|
|
|
+ generation = faiss_query(question, documents, llm)
|
|
|
+ answer += generation
|
|
|
+ answer += "\n"
|
|
|
+ # print(question)
|
|
|
+ # print(generation)
|
|
|
+ return answer
|
|
|
### SQL Grader
|
|
|
|
|
|
def SQL_Grader():
|
|
|
@@ -190,11 +205,11 @@ def SQL_Grader():
|
|
|
def Router():
|
|
|
prompt = PromptTemplate(
|
|
|
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
|
|
|
- You are an expert at routing a user question to a vectorstore or company private data.
|
|
|
+ You are an expert at routing a user question to a 專業知識 or 自有數據.
|
|
|
Use company private data for questions about the informations about a company's greenhouse gas emissions data.
|
|
|
- Otherwise, use the vectorstore for questions on ESG field knowledge or news about ESG.
|
|
|
+ Otherwise, use the 專業知識 for questions on ESG field knowledge or news about ESG.
|
|
|
You do not need to be stringent with the keywords in the question related to these topics.
|
|
|
- Give a binary choice 'company_private_data' or 'vectorstore' based on the question.
|
|
|
+ Give a binary choice '自有數據' or '專業知識' based on the question.
|
|
|
Return the a JSON with a single key 'datasource' and no premable or explanation.
|
|
|
|
|
|
Question to route: {question}
|
|
|
@@ -291,6 +306,28 @@ def company_private_data_search(state):
|
|
|
|
|
|
return {"sql_query": sql_query, "question": question, "generation": generation}
|
|
|
|
|
|
+def additional_explanation(state):
|
|
|
+ """
|
|
|
+
|
|
|
+ Args:
|
|
|
+ state (_type_): _description_
|
|
|
+
|
|
|
+ Returns:
|
|
|
+ state (dict): Appended additional explanation to state
|
|
|
+ """
|
|
|
+
|
|
|
+ print("---ADDITIONAL EXPLANATION---")
|
|
|
+ print(state)
|
|
|
+ question = state["question"]
|
|
|
+ sql_query = state["sql_query"]
|
|
|
+ generation = state["generation"]
|
|
|
+ generation += "\n"
|
|
|
+ generation += generate_additional_detail(sql_query)
|
|
|
+
|
|
|
+ # generation = [company_private_data_result]
|
|
|
+
|
|
|
+ return {"sql_query": sql_query, "question": question, "generation": generation}
|
|
|
+
|
|
|
### Conditional edge
|
|
|
|
|
|
|
|
|
@@ -312,12 +349,12 @@ def route_question(state):
|
|
|
source = question_router.invoke({"question": question})
|
|
|
# print(source)
|
|
|
print(source["datasource"])
|
|
|
- if source["datasource"] == "company_private_data":
|
|
|
+ if source["datasource"] == "自有數據":
|
|
|
print("---ROUTE QUESTION TO TEXT-TO-SQL---")
|
|
|
- return "company_private_data"
|
|
|
- elif source["datasource"] == "vectorstore":
|
|
|
+ return "自有數據"
|
|
|
+ elif source["datasource"] == "專業知識":
|
|
|
print("---ROUTE QUESTION TO RAG---")
|
|
|
- return "vectorstore"
|
|
|
+ return "專業知識"
|
|
|
|
|
|
def grade_generation_v_documents_and_question(state):
|
|
|
"""
|
|
|
@@ -398,48 +435,51 @@ def build_graph():
|
|
|
workflow = StateGraph(GraphState)
|
|
|
|
|
|
# Define the nodes
|
|
|
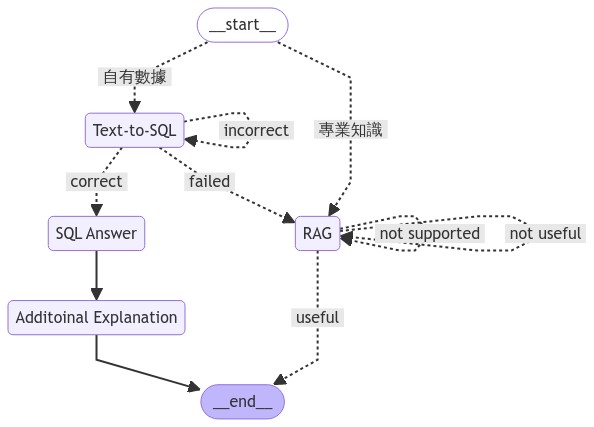
- workflow.add_node("company_private_data_query", company_private_data_get_sql_query, retry=RetryPolicy(max_attempts=5)) # web search
|
|
|
- workflow.add_node("company_private_data_search", company_private_data_search, retry=RetryPolicy(max_attempts=5)) # web search
|
|
|
- workflow.add_node("retrieve_and_generation", retrieve_and_generation, retry=RetryPolicy(max_attempts=5)) # retrieve
|
|
|
+ workflow.add_node("Text-to-SQL", company_private_data_get_sql_query, retry=RetryPolicy(max_attempts=5)) # web search
|
|
|
+ workflow.add_node("SQL Answer", company_private_data_search, retry=RetryPolicy(max_attempts=5)) # web search
|
|
|
+ workflow.add_node("Additoinal Explanation", additional_explanation, retry=RetryPolicy(max_attempts=5)) # retrieve
|
|
|
+ workflow.add_node("RAG", retrieve_and_generation, retry=RetryPolicy(max_attempts=5)) # retrieve
|
|
|
|
|
|
workflow.add_conditional_edges(
|
|
|
START,
|
|
|
route_question,
|
|
|
{
|
|
|
- "company_private_data": "company_private_data_query",
|
|
|
- "vectorstore": "retrieve_and_generation",
|
|
|
+ "自有數據": "Text-to-SQL",
|
|
|
+ "專業知識": "RAG",
|
|
|
},
|
|
|
)
|
|
|
|
|
|
workflow.add_conditional_edges(
|
|
|
- "retrieve_and_generation",
|
|
|
+ "RAG",
|
|
|
grade_generation_v_documents_and_question,
|
|
|
{
|
|
|
- "not supported": "retrieve_and_generation",
|
|
|
+ "not supported": "RAG",
|
|
|
"useful": END,
|
|
|
- "not useful": "retrieve_and_generation",
|
|
|
+ "not useful": "RAG",
|
|
|
},
|
|
|
)
|
|
|
workflow.add_conditional_edges(
|
|
|
- "company_private_data_query",
|
|
|
+ "Text-to-SQL",
|
|
|
grade_sql_query,
|
|
|
{
|
|
|
- "correct": "company_private_data_search",
|
|
|
- "incorrect": "company_private_data_query",
|
|
|
- "failed": END
|
|
|
+ "correct": "SQL Answer",
|
|
|
+ "incorrect": "Text-to-SQL",
|
|
|
+ "failed": "RAG"
|
|
|
|
|
|
},
|
|
|
)
|
|
|
- workflow.add_edge("company_private_data_search", END)
|
|
|
+ workflow.add_edge("SQL Answer", "Additoinal Explanation")
|
|
|
+ workflow.add_edge("Additoinal Explanation", END)
|
|
|
|
|
|
app = workflow.compile()
|
|
|
|
|
|
return app
|
|
|
|
|
|
-def main():
|
|
|
+def main(question: str):
|
|
|
app = build_graph()
|
|
|
#建準去年的類別一排放量?
|
|
|
- inputs = {"question": "溫室氣體是什麼"}
|
|
|
+ # inputs = {"question": "溫室氣體是什麼"}
|
|
|
+ inputs = {"question": question}
|
|
|
for output in app.stream(inputs, {"recursion_limit": 10}):
|
|
|
for key, value in output.items():
|
|
|
pprint(f"Finished running: {key}:")
|
|
|
@@ -448,6 +488,6 @@ def main():
|
|
|
return value["generation"]
|
|
|
|
|
|
if __name__ == "__main__":
|
|
|
- result = main()
|
|
|
+ result = main("建準去年的直接排放排放量?")
|
|
|
print("------------------------------------------------------")
|
|
|
print(result)
|


{kind=link}